Member-only story
Log aggregation with ElasticSearch, Fluentd and Kibana stack on ARM64 Kubernetes cluster
This article was updated on 18/jan/2019 to reflect the updates on the repository, images to 6.5.4 and support to multi-arch cluster composed of X64 (Intel) and ARM64 hosts. The project will be updated so it might be newer than the one described here.
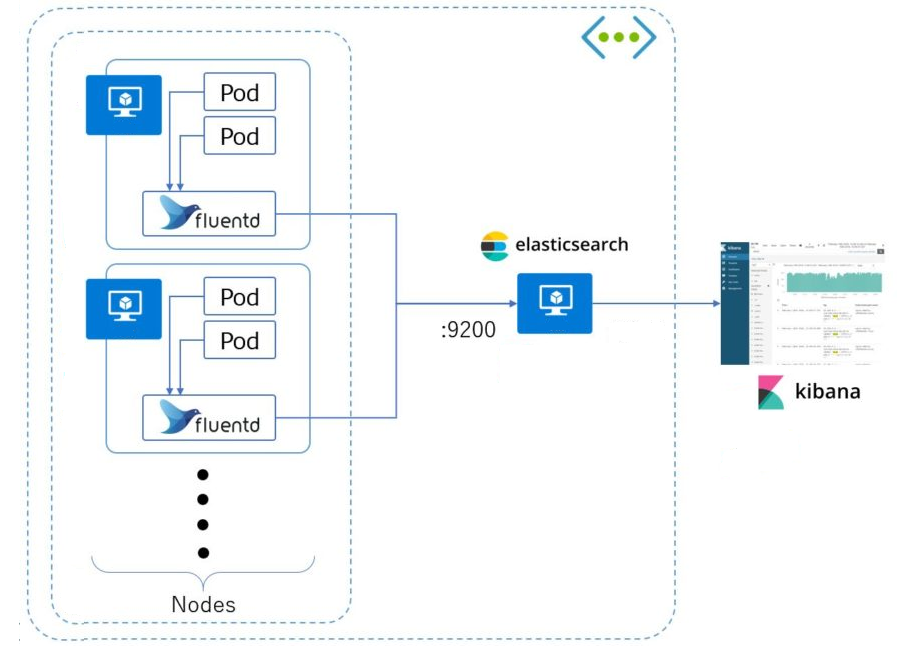
A while back, as a proof of concept, I’ve set a full logging aggregation stack for Kubernetes with ElasticSearch, Fluentd and Kibana on ARM64 SBCs using my Rock64 Kubernetes cluster. This deployment was based on this great project by Paulo Pires with some adaptations.
Since then, Pires discontinued the project but in my fork you can find all the latest files for the project including the manifests for the cluster, image Dockerfiles and build script, Kibana dashboard and detailed information in the Readme: https://github.com/carlosedp/kubernetes-elasticsearch-cluster.
Images
All included images that depend from Java, were built using OpenJDK 1.8.0 181. I recently wrote a post testing the performance for multiple JVMs on ARM64 and found this version provides the best performance. Previously I used Oracle Java in a custom Docker image that is still in the repository.
The project is composed of the ElasticSearch base image, and the ES image with custom configuration for the Kubernetes cluster. The Dockerfiles are a little big so I won’t paste them here but you can check on the repository.
I also created an image for ElasticSearch Curator, a tool to cleanup the ES indexes after a determined amount of days and the Kibana image.
The Fluentd image was based on the Kubernetes addons image found here with minor adaptations.
All the image sources can be found in the repo and are pushed to my Dockerhub account. Having separate images for these steps makes it easier to update separate components . The images are all multi-architecture with X64 (Intel) and ARM64 with a manifest that point to both.
Deployment
The deployment is done on the “logging” namespace and there is a script to automate it and tear it down. You can either use it or do it manually to follow the deployment step by step. The standard…
